
Modern Apps = Modern Data
In a previous blog, I stated that the most challenging problem people tend to hit when modernizing apps is not so much the modernization of the codebase itself, but rather the huge underlying legacy databases coupling everything together and holding you back from real progress despite all modernization efforts in the application domain.
So how do you fix this problem? What are the patterns to use to really get somewhere?
I’ll get there, but before I do that, I’ll first spend some words on the main drivers behind app modernization, and what the typical approach is for selecting what to modernize and how. With this context, it will become clear why the data should be modernized as well and how to do that effectively.
Why do we modernize applications?
When organizations set out to modernize their application portfolio, there are usually 2 main drivers:
- operational excellence (cost savings) - when applications are moved onto modern platforms using modern deployment practices, organizations can more efficiently use (cloud) infrastructure, can save on time and resources due to better performing IT and DevOps workstreams, and will incur fewer SLA penalties and less missed revenue due to outages
- agility (revenue growth) - traditional development practices, architectures, and technology hold back business agility and innovation. What was good enough in the early 00’s isn’t good enough today, especially if you want to compete in the digital domain. And who doesn’t? So in order to innovate and reduce the time to market organizations are looking to break up monoliths into smaller easier to maintain and faster to ship components, and embrace modern software development practices.
It may come as a surprise to business people that modernization is an ongoing effort, so it’s never done, and it’s not a project you can finish. At the same time, technologists should realize modernization is not a technical goal. It’s OK to have legacy stuff and keep it around: the only valid drivers for spending money on change are those above, and they are business drivers.
What do we modernize?
Going all in and modernizing everything is a bad idea: it will never be finished, it will cost tons of money, and you will end up where you started.
So a good app modernization effort starts by investigating where to invest. In general you’ll want to keep only apps that contribute to your core business and replace the rest with Commercial Off The Shelve (COTS) or SaaS apps. Then you test the remainder of the app portfolio and find out their technological state and the business value they provide. Based on that exercise, you can relatively quickly find out how to deal with it:
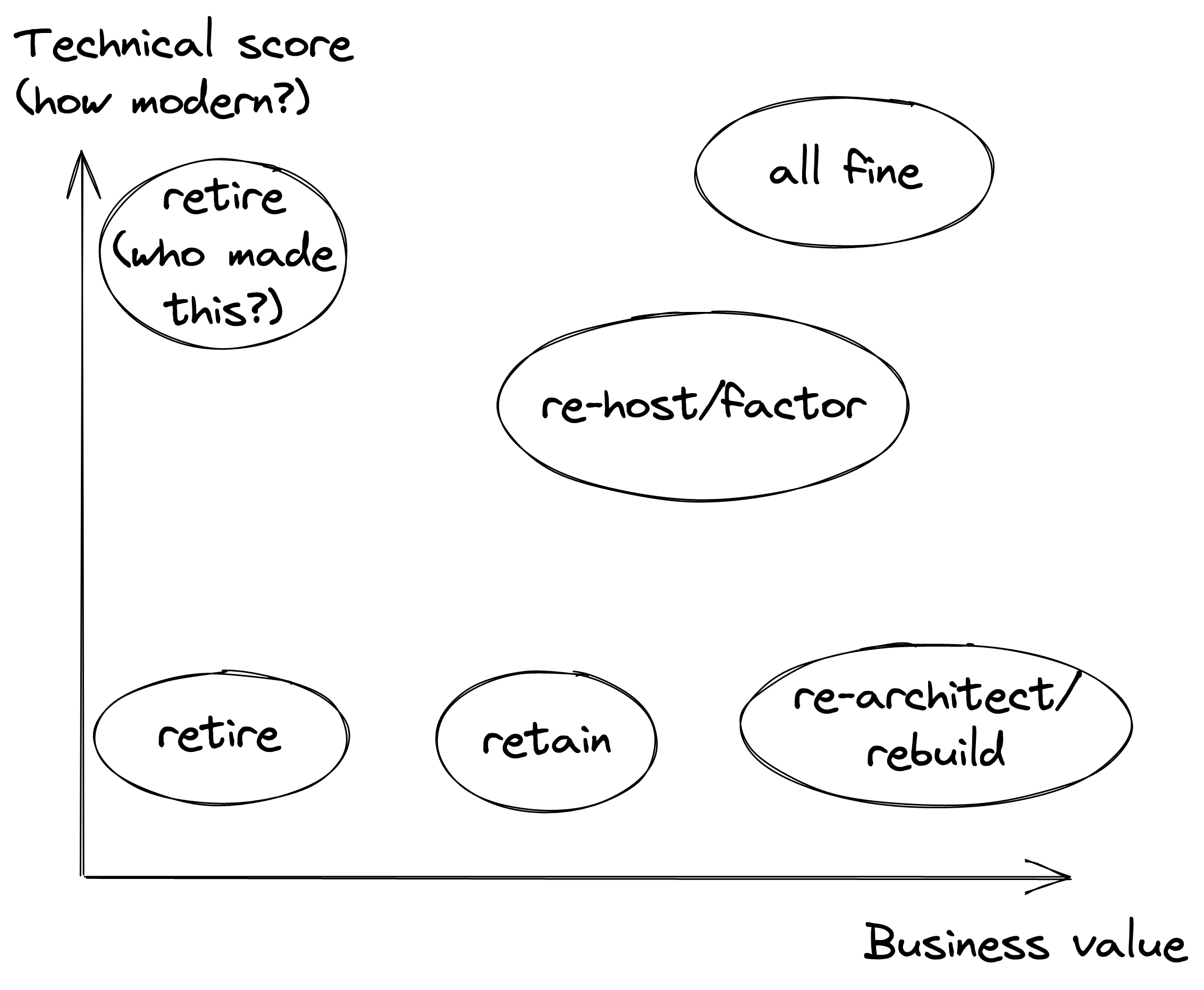
Now you’ll want to retire (shut down) all apps with little or no business value, retain (keep and put a fence around) the legacy stuff that has some business value but hardly ever changes.
That leaves you with 3 main categories:
- ‘all fine’ - modern apps with a good business value. Likely built according to modern development practices, microservices based, embracing cloud models and deployment strategies. No effort required.
- re-host/re-factor - these apps are still OK enough to keep around. You don’t want to invest a lot, but a simple lift & shift to a container and/or cloud platform, or perhaps small modifications to make that work are in order. You do this to generate quick wins and capitalize on operational efficiency.
- re-architect/build - these are the apps that bring tremendous business value but you can’t capitalize and innovate because of the technical state they are in. You’ll likely want to rebuild these completely in a move to unlock the agility you need.
So how do we re-build?
We’ll just rebuild all the legacy stuff with high business value and we’re done, right? Well…it’s not that simple. Yes, it works for relatively small, self-contained applications. However, this doesn’t scale very well: a big bang modernization of a large codebase is often not realistic, may be unnecessary, and is extremely risky.
The accepted approach is to take this large (monolithic) app, and again apply the same logic as above, but now for the one app: what part would we like to change most often in order to speed up innovation? Then you only rebuild that part and introduce an API to lift the strong coupling between the legacy ‘core’ app (we then retain or replatform/rehost), and the newly built part we apply all modern practices to. This approach, when repeated, is known as the strangler pattern.
It’s a perfect setup, except for one thing:

A shared database is a problem
A shared database short-circuits all your efforts to decouple the legacy and modern parts in the application layer, e.g.:
- the scaling potential of the modern part will be tied to the scalability of the legacy database: your modern app may be infinitely (auto-)scaleable in terms of compute but will bottleneck hard on data access
- data schema changes in the new part are tied to the release cadence of the legacy one, undermining your release frequency and thus your pace of innovation
- it will be hard and inefficient to move parts of the app to multi/hybrid/poly cloud due to the data being only in one place: even if you have an direct connection to the cloud in the form of Azure ExpressRoute/AWS Direct Connect or something similar you’ll still have latency and a lot of traffic
In application modernization done right, you also decouple and modernize the data layer.
Modern databases
In a 2021 analyst report titled ‘The Impact of Application Modernization on the Data Layer’, IDC found:
- modern (microservices) based applications are 56% developed from scratch, where 44% were refactored legacy applications.
- 47% of these modern apps rely on a database. The rest is completely stateless, which prevents the data problem above entirely, but also greatly limits the possible use cases
- key-value databases are perceived as better-suited and more responsive to the needs of modern apps, where the preference is for vendor-supplied over public cloud provider or community open source
Let me rephrase this: there are still use cases where the trusty old RDBMS is the best pick, but in all likelihood you will want to use fit-for-purpose databases (like key-value, document, graph) over classical RDBMS systems for modern apps.
For apps developed from scratch this is easy: you pick the database that’s best for you. But how do you modernize part of your app and its data to utilize a modern database when the legacy part is still using a massive Death Star RDBMS?
Data modernization patterns
As with code, a big bang scenario where you cut up the legacy database is a recipe for disaster: you’ll take on a huge task, and will have nothing to show for it until you succeed (or quite likely fail). It also comes with a risk to the legacy app as you are changing its data schemas as well.
So how do you seperate out part of the data in a way that is reliable, allows incremental progress, and carries no risk to the existing database?
Log reading (change data capture)
The approach that’s used more and more these days and is becoming a standard of sorts, is to leverage the RDBMS logs. Since all database changes are written to logs, a process reading these logs and capturing the changes can be used to build a completely independent view of the data someplace else.
A number of modern streaming and data platform vendors provide tooling to set this up. As always, if you value performance and availability - and you do! - Redis is the obvious choice. An example architecture based on this using Redis:
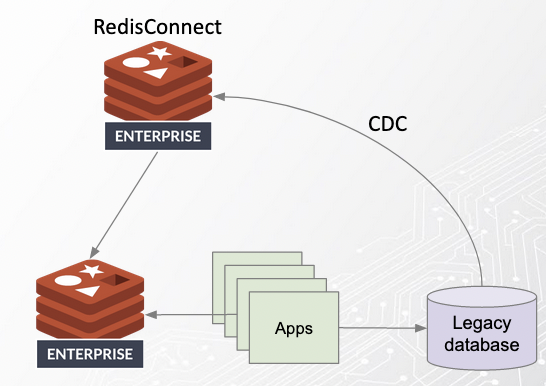
Here, Redis Connect is (through change data capture/CDC), filling a modern data structure in a Redis Enterprise database. Legacy apps can continue to use the legacy database, where modern (microservices) apps can be build to use only the data they need (and own), containing their microdata in the modern Redis Enterprise data platform.
This is a giant leap forward as it uncouples our modern apps/data from the release cadence of the old application. Moreover, it makes sure we now can really scale the modern apps without bottlenecking on the datalayer.
Lifting data gravity & embracing cloud
Taking this one step further, we can create an architecture for modernizing applications anywhere:
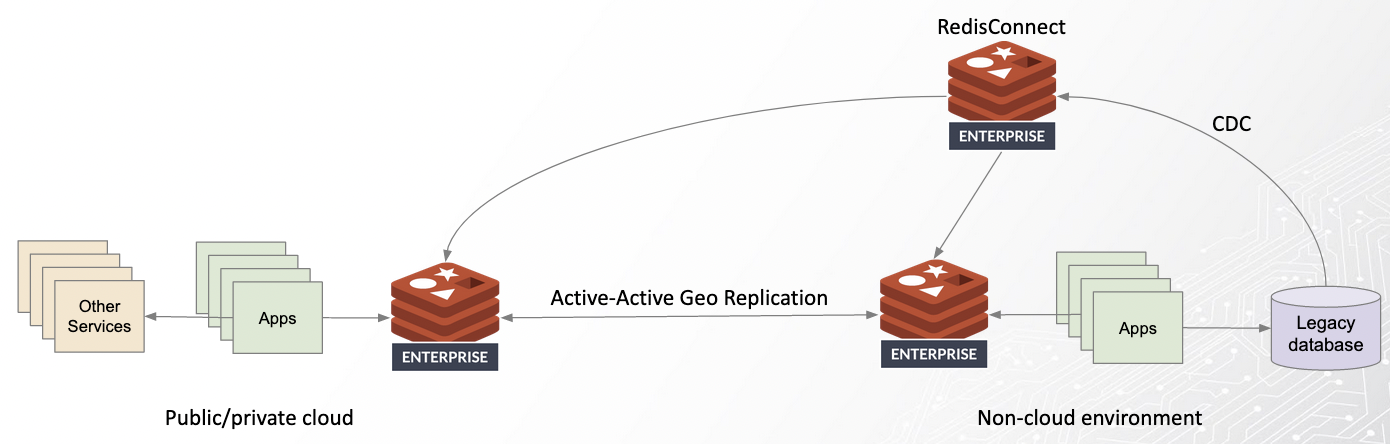
The starting point is an environment (likely non-cloud and on-prem) hosting apps and their legacy databases. As we saw before, we can use CDC in the form of Redis Connect to enable the modernization of apps and their data on that same environment. However, we can also setup Redis Enterprise on a different cloud environment (anywhere in the world), and connect active-active geo replication between the Redis Enterprise instances. This way we’ll have the same data available to all modern apps in both environments.
Why would we do that? Doing so effectively lifts the data gravity: we can deploy the modernized applications to a new environment without suffering high latency or egress charges. Finally, we’re no longer stuck to deploying modern apps to the same (non-cloud) environment hosting the legacy data.
This provides a unique architecture for incremental, risk-free modernization of apps and their data and for successful cloud migrations. Finally we are all set for unlocking that business agility and capitalizing on operational efficiency.