
vRO API Explorer update
The vRealize Orchestrator API Explorer is a popular reference site for people working with vRealize Orchestrator (vRO). Flores Eken and I built it 4 years ago when working on a huge private cloud project for which vRO was instrumental. We were so frustrated in our daily work by the poor design and limited possibilities of the built-in API Explorer in the vRO client we developed this online reference and search.
Statistics
We personally moved on to work with other tools and platforms but vroapi.com remains hugely popular. The monthly stats:
- 1400 users
- 15k pageviews
- 5 pages/session
- 0 sponsors
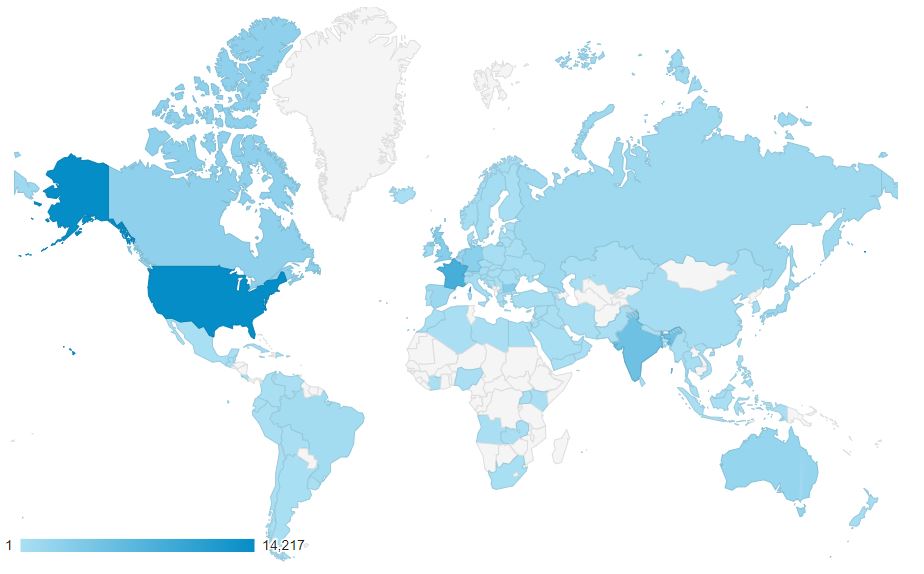 Geo by country
Geo by country
Our users are from all over the world, but most of our users are from the US (30.6%), with India (9.27%) and France (8.91%) as second and third.
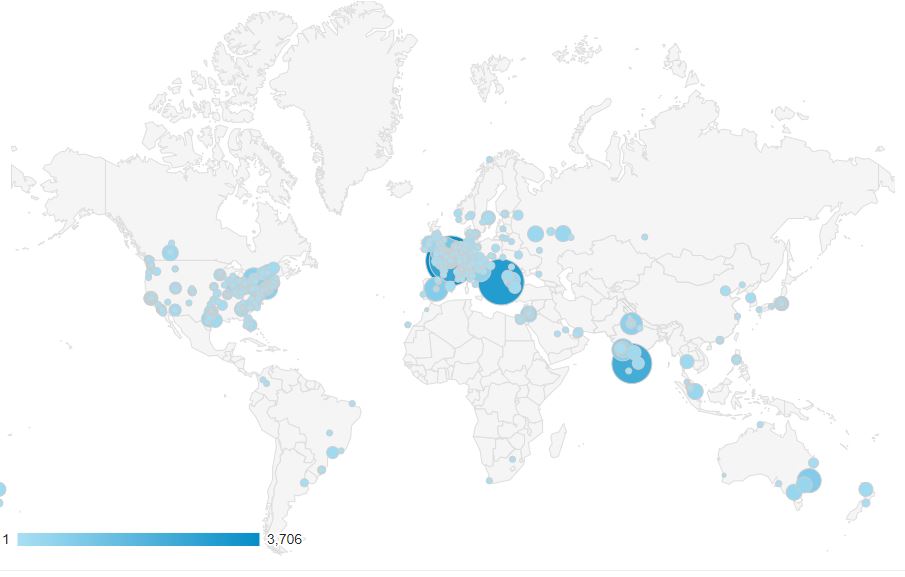 Geo by city
Geo by city
The city view is also interesting, with Bengaluru (India), Paris (France) and Sofia (Bulgaria) as top runners. This also shows the areas with the most vroapi and by extension vRO adoption. A funny detail here is that Sofia is the location of the VMware Center of Excellence, and Bengaluru also has a large VMware office.
On sponsors
It’s mentioned above: vroapi.com has no sponsors. This is not intentional on our end. As it stands, we provide this as a free service that’s costing us (time = money), so we will likely discontinue it sometime in the future when the last people we know personally stop working with vRO.
Improvements
As we have this many people using it we keep improving vroapi regularly. Between 2015 and now we migrated from .NET Core RC1 to .NET Core 2.2 and from Visual Studio Professional 2015 to Visual Studio Code. From the start, we’ve used an in-memory object graph which makes the site insanely fast.
Initially, our plugin metadata was distributed as xml files together with the code. While this made for convenient deployments, it required us to manually extract the metadata xml from the plugin zip for every new plugin. This was not so bad for the first handful of plugins, but it quickly became tedious. The next step was to automate by parsing the plugin zip at startup. As a bonus, this enabled us to load other material from the zip (custom icons). Obviously, it’s not a good idea to distribute binaries (zips) together with the source code, so we moved to loading the plugins from a S3 repository.
Java classfile parsing
Ultimately, the quality of the data on the site still depends on the xml metadata. Apparently most vendors don’t use automation or scripts to generate the metadata from the Java classes used in the plugin, resulting in typos, wrong types, missing methods and objects. It varies from plugin to plugin, but for some it’s really bad. In order to ‘repair’ some of this wrong information, we started to augment the advertised metadata from the plugin xmls with metadata obtained from parsing the binary Java classfiles inside the plugins. It’s a testament to the raw performance of .NET Core that we can load 1000s of Java classes in 100s of plugins at startup, fix the metadata, and still be up in a few seconds.